✅ CUDA编程快速入门指南 🔥
全面介绍 CUDA 编程模型、内存模型及常见算子优化技术,帮助你高效实现和优化 AI 算法
CUDA 是连接 AI 算法与 GPU 硬件的桥梁,负责把高层的数学计算翻译成 GPU 能最高效执行的机器指令。本文从编程模型、内存模型讲起,到 Reduce/GEMM/Softmax 三大经典算子的实现与优化,再到 FlashAttention 系列 Attention 算子和 Triton 编译器,系统覆盖 AI Infra 从业者需要掌握的 CUDA 编程基础。
📑 目录
- 1. 环境配置
- 2. CUDA 编程模型
- 3. 内存模型
- 4. 关键概念
- 5. 第一个完整程序:向量加法
- 6. 常见算子实现与优化
- 7. Attention 算子
- 8. AI 编译器
- 9. 性能分析工具
- 10. 自我检验清单
- 参考资料
1. 环境配置
1.1 硬件要求
- NVIDIA GPU(Compute Capability >= 7.0,即 Volta 架构及以上)
- 建议至少 8GB 显存用于算子开发和调试
1.2 软件安装
安装 CUDA Toolkit
# Ubuntu 22.04
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get install cuda-toolkit-12-3
# 设置环境变量(加到 ~/.bashrc 或 ~/.zshrc)
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
验证安装
nvcc --version # 查看 CUDA 编译器版本
nvidia-smi # 查看 GPU 信息和驱动版本
1.3 编译基础
CUDA 程序使用 .cu 扩展名,用 nvcc 编译:
# 基础编译
nvcc hello.cu -o hello
# 指定 GPU 架构(推荐)
nvcc -arch=sm_80 hello.cu -o hello # A100
nvcc -arch=sm_90 hello.cu -o hello # H100
# 查看寄存器和共享内存使用量(调优时必用)
nvcc -Xptxas -v hello.cu -o hello
2. CUDA 编程模型
2.1 核函数(Kernel)
核函数是在 GPU 上执行的函数,使用 __global__ 关键字声明。调用时通过 <<<gridDim, blockDim>>> 语法指定并行规模:
// 声明核函数
__global__ void myKernel(float* data, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
data[idx] *= 2.0f;
}
}
// 调用核函数:128 个 Block,每个 Block 256 个线程
myKernel<<<128, 256>>>(data, n);
CUDA 有三种函数修饰符:
| 修饰符 | 执行位置 | 调用方 | 说明 |
|---|---|---|---|
__global__ | GPU | CPU(或 GPU) | 核函数,启动 GPU 并行执行 |
__device__ | GPU | GPU | 设备函数,只能被核函数或其他设备函数调用 |
__host__ | CPU | CPU | 普通 CPU 函数(默认,可省略) |
__host__ 和 __device__ 可以同时使用,让编译器为 CPU 和 GPU 各生成一份代码。
2.2 Grid / Block / Thread 三层线程层级
CUDA 将线程组织为三层结构,这是理解并行编程的关键。可以把它比喻为”学校 / 班级 / 学生”——Grid 是整个学校,Block 是一个班级,Thread 是班里的每个学生,每个学生独立做自己那份作业,但同一个班级的学生可以通过”黑板”(Shared Memory)互相交流。
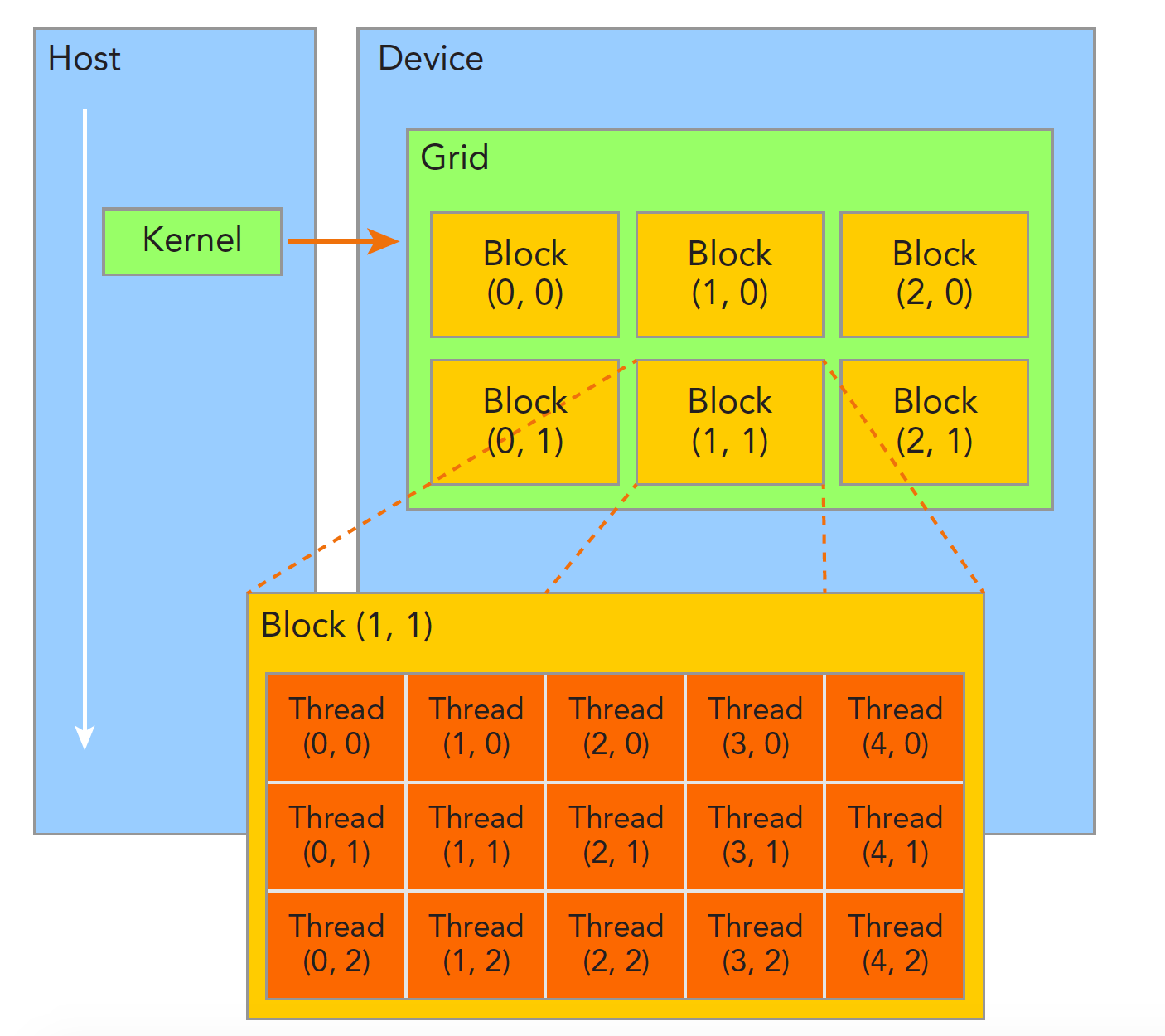
维度与索引
Grid 和 Block 都支持 1D、2D、3D 维度。全局线程索引的计算方式:
// 1D 情况(最常用)
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// 2D 情况(矩阵运算常用)
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
// 使用 dim3 指定 2D 维度
dim3 blockDim(16, 16); // 每个 Block 16x16 = 256 个线程
dim3 gridDim(
(width + 15) / 16, // x 方向 Block 数量
(height + 15) / 16 // y 方向 Block 数量
);
kernel<<<gridDim, blockDim>>>(data, width, height);
设计约束
| 参数 | 限制 |
|---|---|
| Block 内线程数 | 最多 1024 |
| Grid 每个维度的 Block 数 | 最多 2^31 - 1 (x), 65535 (y, z) |
| 每 SM 活跃线程数 | 最多 2048(64 个 Warp) |
| 每 SM 活跃 Block 数 | 最多 32 |
Block Size 选择经验
- 256:大多数场景的最佳起点(8 个 Warp)
- 128:访存密集型任务,需要更多 Block 并发
- 512-1024:计算密集型任务,注意寄存器和共享内存压力
- 始终是 32 的倍数:与 Warp 大小对齐,避免浪费
2.3 内存管理
CUDA 需要显式管理 CPU(Host)和 GPU(Device)之间的内存:
float* d_data; // d_ 前缀表示 device 内存
// 1. 分配 GPU 内存
cudaMalloc(&d_data, n * sizeof(float));
// 2. CPU → GPU 数据传输
cudaMemcpy(d_data, h_data, n * sizeof(float), cudaMemcpyHostToDevice);
// 3. 执行 kernel
myKernel<<<gridDim, blockDim>>>(d_data, n);
// 4. GPU → CPU 数据传输
cudaMemcpy(h_data, d_data, n * sizeof(float), cudaMemcpyDeviceToHost);
// 5. 释放 GPU 内存
cudaFree(d_data);
异步传输与 Stream
默认情况下,cudaMemcpy 是同步的(会阻塞 CPU)。使用 Stream 可以实现异步传输和计算重叠:
cudaStream_t stream;
cudaStreamCreate(&stream);
// 异步传输(CPU 不会阻塞)
cudaMemcpyAsync(d_data, h_data, size, cudaMemcpyHostToDevice, stream);
// 在同一 stream 中启动 kernel(会等传输完成后执行)
myKernel<<<gridDim, blockDim, 0, stream>>>(d_data, n);
// 异步回传结果
cudaMemcpyAsync(h_data, d_data, size, cudaMemcpyDeviceToHost, stream);
// 等待 stream 中所有操作完成
cudaStreamSynchronize(stream);
cudaStreamDestroy(stream);
使用异步传输时,CPU 端内存必须是锁页内存(Pinned Memory),否则传输速度会大幅下降:
float* h_pinned;
cudaMallocHost(&h_pinned, size); // 分配锁页内存,传输速度提升 2-3x
// ... 使用 ...
cudaFreeHost(h_pinned); // 释放锁页内存
2.4 错误处理
CUDA API 调用可能失败,生产代码中必须检查错误:
#define CUDA_CHECK(call) do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA error at %s:%d: %s\n", \
__FILE__, __LINE__, cudaGetErrorString(err)); \
exit(EXIT_FAILURE); \
} \
} while(0)
// 使用
CUDA_CHECK(cudaMalloc(&d_data, size));
CUDA_CHECK(cudaMemcpy(d_data, h_data, size, cudaMemcpyHostToDevice));
// kernel 启动后检查错误
myKernel<<<gridDim, blockDim>>>(d_data, n);
CUDA_CHECK(cudaGetLastError()); // 检查启动参数错误
CUDA_CHECK(cudaDeviceSynchronize()); // 检查执行错误
3. 内存模型
CUDA 的内存层次是性能优化的核心。“内存访问模式决定运行速度”——这是 CUDA 编程最重要的直觉。
3.1 存储层次总览
寄存器 (Registers) ← 最快,每线程私有
│ ~20 TB/s, ~0 cycle
▼
共享内存 (Shared Memory) ← 可编程的片上缓存,Block 内共享
│ ~20 TB/s, ~20-30 cycles
▼
L1 / L2 Cache ← 自动管理的硬件缓存
│ L2: ~12 TB/s, ~200 cycles
▼
全局内存 (Global Memory/HBM) ← "显存",所有线程可访问
│ ~3.35 TB/s (H100), ~400-600 cycles
▼
主机内存 (Host/CPU Memory) ← 需要通过 PCIe 传输
~64 GB/s (PCIe 5.0)
3.2 寄存器(Registers)
寄存器是最快的存储,kernel 中的局部变量默认分配在寄存器中:
__global__ void kernel(float* data, int n) {
// a, b, result 都在寄存器中
float a = data[threadIdx.x];
float b = a * 2.0f;
float result = a + b;
data[threadIdx.x] = result;
}
注意事项:
- 每个 SM 的寄存器总量有限(H100 每 SM 65536 个 32-bit 寄存器)
- 每个线程用的寄存器越多,SM 上能同时运行的线程就越少(影响 Occupancy)
- 寄存器用完会”溢出”到 Local Memory(实际是 HBM),速度骤降
查看寄存器使用:
nvcc -Xptxas -v kernel.cu
# 输出: ptxas info: Used 32 registers, 0 bytes smem
# 如果看到 "stack frame" 或 "spill" 说明有溢出
3.3 共享内存(Shared Memory)
共享内存是程序员可控的片上高速缓存,相当于同一个 Block 内线程共享的”黑板”——任何一个线程往上面写了东西,同 Block 的其他线程都能看到,而且读写速度比全局内存快得多。它的典型用途是缓存从全局内存加载的数据,供 Block 内线程重复使用。
__global__ void sharedMemDemo(float* input, float* output, int n) {
// 静态分配共享内存
__shared__ float smem[256];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// 1. 从全局内存加载到共享内存
if (idx < n) {
smem[threadIdx.x] = input[idx];
}
// 2. 同步:确保所有线程都加载完毕
__syncthreads();
// 3. 从共享内存读取(可以读邻居的数据,速度极快)
if (idx < n && threadIdx.x > 0) {
output[idx] = smem[threadIdx.x] + smem[threadIdx.x - 1];
}
}
动态共享内存——大小在 kernel 启动时指定:
extern __shared__ float dynamic_smem[];
kernel<<<gridDim, blockDim, sharedMemBytes>>>(args);
3.4 全局内存(Global Memory / HBM)
全局内存就是”显存”,容量最大但速度最慢。cudaMalloc 分配的内存、kernel 参数中的指针都指向全局内存。
合并访问(Coalesced Access) 是全局内存优化的黄金法则:同一个 Warp 内的 32 个线程应该访问连续的内存地址,这样硬件可以将多次访问合并为少量内存事务。打个比方,合并访问就像一排人依次从传送带上拿东西,一次就能拿完;如果每个人跳着拿,传送带要来回好多次,效率大打折扣。
// 好:合并访问——相邻线程访问相邻地址
float val = data[threadIdx.x]; // 一次 128B 事务搞定
// 坏:跨步访问——相邻线程访问间隔地址
float val = data[threadIdx.x * stride]; // 多次事务,浪费带宽
// 坏:随机访问——完全无法合并
float val = data[random_index[threadIdx.x]];
数据布局优化——AoS 转 SoA:
// AoS (Array of Structures) —— 对 GPU 不友好
struct Particle { float x, y, z, w; };
Particle particles[N];
// 访问所有 x:particles[0].x, particles[1].x, ... 跨步为 16B
// SoA (Structure of Arrays) —— 对 GPU 友好
struct Particles {
float x[N]; // 所有 x 连续存放
float y[N];
float z[N];
float w[N];
};
// 访问所有 x:连续内存,完美合并
3.5 常量内存(Constant Memory)
适合所有线程读取相同值的场景(广播模式),有专用缓存:
__constant__ float coefficients[256]; // 最大 64KB
// CPU 端写入
cudaMemcpyToSymbol(coefficients, h_coeffs, 256 * sizeof(float));
// GPU 端读取(所有线程读同一地址时最高效)
float c = coefficients[idx];
3.6 内存模型总结
| 存储类型 | 位置 | 作用域 | 速度 | 容量 | 程序员控制 |
|---|---|---|---|---|---|
| 寄存器 | 片上 | 线程私有 | 最快 | 每线程 ~255 个 | 自动分配 |
| 共享内存 | 片上 | Block 共享 | 极快 | 每 SM ~228KB | 手动管理 |
| L1/L2 Cache | 片上 | 自动 | 快 | L2 ~50MB | 自动(可提示) |
| 全局内存 | HBM | 所有线程 | 慢 | 80-192GB | 手动管理 |
| 常量内存 | HBM + 缓存 | 所有线程(只读) | 广播时快 | 64KB | 手动管理 |
4. 关键概念
4.1 Warp
Warp 是 GPU 执行的最小调度单位,由 32 个连续线程 组成。同一个 Warp 内的线程在同一时刻执行相同的指令(SIMT)。可以把 Warp 想象成一排 32 个士兵齐步走,步调必须一致——如果有人要向左转、有人要向右转,就只能先让一拨人转完,再让另一拨人转,效率减半。
Block (256 threads)
├── Warp 0: Thread 0-31
├── Warp 1: Thread 32-63
├── Warp 2: Thread 64-95
├── ...
└── Warp 7: Thread 224-255
Warp Divergence(分支发散)
当 Warp 内的线程走不同的 if/else 分支时,两个分支必须串行执行,导致性能减半:
// 坏:Warp 内一半线程走 if,一半走 else
if (threadIdx.x < 16) {
doA(); // Warp 内 thread 0-15 执行,16-31 等待
} else {
doB(); // Warp 内 thread 16-31 执行,0-15 等待
}
// 好:让整个 Warp 走同一分支
if (threadIdx.x / 32 < someValue) { // 以 Warp 为粒度分支
doA(); // 整个 Warp 执行
}
Warp 级原语
Warp 内线程可以直接交换数据,无需共享内存:
// Warp Shuffle:线程间直接交换寄存器值
float val = __shfl_down_sync(0xFFFFFFFF, myVal, delta);
// 线程 i 获取线程 i+delta 的值
float val = __shfl_xor_sync(0xFFFFFFFF, myVal, mask);
// 线程 i 获取线程 i^mask 的值(蝶形交换)
// Warp 级归约(Volta+)
float sum = __reduce_add_sync(0xFFFFFFFF, myVal);
// 一条指令完成 Warp 内求和
4.2 Bank Conflict
共享内存被分为 32 个 Bank,每个 Bank 宽度为 4 字节。同一 Warp 内的不同线程如果访问同一 Bank 的不同地址,就会产生 Bank Conflict,访问变为串行。可以把 Shared Memory 的 32 个 Bank 想象成银行的 32 个柜台,如果多个线程同时排到同一个柜台,就得排队等候;理想情况是每个线程各去一个柜台,大家同时办完。
__shared__ float smem[32][32];
// 无 Bank Conflict:每个线程访问不同 Bank
float val = smem[0][threadIdx.x]; // 线程 i 访问 Bank i
// 32-way Bank Conflict:所有线程访问同一 Bank
float val = smem[threadIdx.x][0]; // 列访问,所有线程都访问 Bank 0
// 经典解决方案:Padding
__shared__ float smem[32][33]; // 多加一列,错开 Bank
float val = smem[threadIdx.x][0]; // 现在线程 i 访问 Bank i,无冲突
检测 Bank Conflict
ncu --metrics l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld.sum ./app
# 输出为 0 表示无 Bank Conflict
4.3 Occupancy
Occupancy = 实际活跃 Warp 数 / SM 最大 Warp 数。它反映了 GPU 并行度的利用程度。
影响 Occupancy 的三个因素:
| 因素 | 影响 | 调优方向 |
|---|---|---|
| 每线程寄存器数 | 寄存器多 → 每 SM 能容纳的线程少 | 减少局部变量、控制循环展开 |
| 每 Block 共享内存 | 共享内存多 → 每 SM 能容纳的 Block 少 | 合理分配,避免浪费 |
| Block 大小 | 太小或太大都不好 | 256 是常用起点 |
// 让编译器帮你计算最优 Block Size
int minGridSize, blockSize;
cudaOccupancyMaxPotentialBlockSize(&minGridSize, &blockSize, myKernel, 0, 0);
printf("Optimal block size: %d\n", blockSize);
重要提醒:Occupancy 不是越高越好。对于 Tensor Core 密集型 kernel,25-50% 的 Occupancy 就可能达到峰值性能。先保证没有寄存器溢出,再考虑 Occupancy。
5. 第一个完整程序:向量加法
把前面的知识串起来,写一个完整的向量加法程序:
#include <stdio.h>
#include <cuda_runtime.h>
#define CUDA_CHECK(call) do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA error at %s:%d: %s\n", \
__FILE__, __LINE__, cudaGetErrorString(err)); \
exit(EXIT_FAILURE); \
} \
} while(0)
// 核函数:向量加法
__global__ void vectorAdd(const float* a, const float* b, float* c, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
c[idx] = a[idx] + b[idx];
}
}
int main() {
const int N = 1 << 20; // 1M 元素
size_t bytes = N * sizeof(float);
// 分配主机内存并初始化
float* h_a = (float*)malloc(bytes);
float* h_b = (float*)malloc(bytes);
float* h_c = (float*)malloc(bytes);
for (int i = 0; i < N; i++) {
h_a[i] = 1.0f;
h_b[i] = 2.0f;
}
// 分配设备内存
float *d_a, *d_b, *d_c;
CUDA_CHECK(cudaMalloc(&d_a, bytes));
CUDA_CHECK(cudaMalloc(&d_b, bytes));
CUDA_CHECK(cudaMalloc(&d_c, bytes));
// Host → Device
CUDA_CHECK(cudaMemcpy(d_a, h_a, bytes, cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemcpy(d_b, h_b, bytes, cudaMemcpyHostToDevice));
// 计算 Grid 和 Block 维度
int blockSize = 256;
int gridSize = (N + blockSize - 1) / blockSize;
// 启动 Kernel
vectorAdd<<<gridSize, blockSize>>>(d_a, d_b, d_c, N);
CUDA_CHECK(cudaGetLastError());
// Device → Host
CUDA_CHECK(cudaMemcpy(h_c, d_c, bytes, cudaMemcpyDeviceToHost));
// 验证
for (int i = 0; i < N; i++) {
if (h_c[i] != 3.0f) {
printf("Error at index %d: %f\n", i, h_c[i]);
break;
}
}
printf("Vector addition completed successfully!\n");
// 释放
free(h_a); free(h_b); free(h_c);
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
return 0;
}
编译运行:
nvcc -arch=sm_80 vector_add.cu -o vector_add && ./vector_add
6. 常见算子实现与优化
掌握以下三个经典算子的实现与优化,是 CUDA 编程的必修课。它们覆盖了归约、矩阵乘法、归一化三种最基础的计算模式。
6.1 Reduce(并行归约)
Reduce 是将一组数据聚合为一个值(如求和、求最大值)的操作。它是理解 CUDA 并行思维的最佳入门。
基本思路:树形规约
想象 1024 个人各持一个数,两两配对相加,每轮人数减半——仅需 10 轮就能得到总和。GPU 上的实现就是让每个 Block 内的线程协作完成这个过程:
初始:[1, 2, 3, 4, 5, 6, 7, 8]
第1轮(step=4):tid 0~3 各与 tid+4 相加 → [6, 8, 10, 12, ...]
第2轮(step=2):tid 0~1 各与 tid+2 相加 → [16, 20, ...]
第3轮(step=1):tid 0 与 tid+1 相加 → [36, ...]
朴素实现
// 树形归约:步长从 blockDim/2 开始缩小,保证低编号线程连续工作
__global__ void reduce_base(float* input, float* output, int n) {
extern __shared__ float smem[];
int tid = threadIdx.x;
int gid = blockIdx.x * blockDim.x + threadIdx.x;
// 将全局内存数据加载到共享内存
smem[tid] = (gid < n) ? input[gid] : 0.0f;
__syncthreads();
// 步长从大到小:保证同一 Warp 内线程要么全部工作,要么全部空闲
for (int step = blockDim.x / 2; step > 0; step >>= 1) {
if (tid < step) {
smem[tid] += smem[tid + step];
}
__syncthreads();
}
// 每个 Block 的结果写回全局内存
if (tid == 0) output[blockIdx.x] = smem[0];
}
💡 步长从大到小(而非从小到大)是关键:这保证活跃线程编号连续,同一 Warp 内不会出现”一半工作一半空闲”的 Warp Divergence,硬件调度效率大幅提升。
优化 1:展开最后一个 Warp
当 step <= 32 时,只有 1 个 Warp(32 线程)在工作。Warp 内线程天然 SIMT 锁步执行,不需要 __syncthreads()。直接展开这几轮循环可以省去多余的同步屏障开销:
__device__ void warpReduce(volatile float* smem, int tid) {
smem[tid] += smem[tid + 32];
smem[tid] += smem[tid + 16];
smem[tid] += smem[tid + 8];
smem[tid] += smem[tid + 4];
smem[tid] += smem[tid + 2];
smem[tid] += smem[tid + 1];
}
__shfl_down_sync(mask, val, delta)让每个线程直接读取lane_id + delta的寄存器值,比 Shared Memory 访问更快(无地址计算、无 Bank Conflict、延迟更低)。
优化 2:每线程处理多个元素
在基础版本中,每个线程只加载 1 个元素。通过让每个线程在加载阶段就先做一次加法(负责 2 个元素),可以在不增加 Block 数量的前提下翻倍处理数据量,提升线程利用率:
__global__ void reduce_opt(float* input, float* output, int n) {
extern __shared__ float smem[];
int tid = threadIdx.x;
int gid = blockIdx.x * (blockDim.x * 2) + threadIdx.x;
// 每个线程加载并累加 2 个元素
float val = 0.0f;
if (gid < n) val += input[gid];
if (gid + blockDim.x < n) val += input[gid + blockDim.x];
smem[tid] = val;
__syncthreads();
// 树形归约(step > 32 部分)
for (int step = blockDim.x / 2; step > 32; step >>= 1) {
if (tid < step) smem[tid] += smem[tid + step];
__syncthreads();
}
// 最后 Warp 用 Shuffle 规约
if (tid < 32) {
warpReduce(smem, tid);
}
if (tid == 0) {
output[blockIdx.x] = smem[0];
}
}
📌 Reduce 是典型的 Memory-Bound 操作(算术强度仅 0.25 FLOP/Byte),优化核心在于提升内存带宽利用率。更多进阶优化(向量化加载
float4、Grid Stride Loop、模板展开等)可参考 CUDA Reduce 算子优化 一文。
6.2 GEMM(矩阵乘法)
GEMM(General Matrix Multiply)是大模型的计算核心——线性层和 Attention 本质上都是矩阵乘法。
朴素实现
// C = A * B,A: MxK, B: KxN, C: MxN
__global__ void gemmNaive(float* A, float* B, float* C,
int M, int N, int K) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < M && col < N) {
float sum = 0.0f;
for (int k = 0; k < K; k++) {
sum += A[row * K + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}
问题:每个线程独立从全局内存读取 A 的一行和 B 的一列,大量重复读取。
优化 1:Shared Memory Tiling(分块)
核心思想:将大矩阵分成小块(Tile),每次将一个 Tile 加载到 Shared Memory 中,Block 内所有线程共享使用。这就像搬家时家具太多一次搬不完,于是分批搬到桌上再整理——每批数据搬进快速的 Shared Memory 后,所有线程可以反复使用,避免每次都回慢速的全局内存去取。
#define TILE_SIZE 32
__global__ void gemmTiled(float* A, float* B, float* C,
int M, int N, int K) {
__shared__ float As[TILE_SIZE][TILE_SIZE];
__shared__ float Bs[TILE_SIZE][TILE_SIZE];
int row = blockIdx.y * TILE_SIZE + threadIdx.y;
int col = blockIdx.x * TILE_SIZE + threadIdx.x;
float sum = 0.0f;
// 沿 K 维度分块迭代
for (int t = 0; t < (K + TILE_SIZE - 1) / TILE_SIZE; t++) {
// 协作加载 Tile 到共享内存
int aCol = t * TILE_SIZE + threadIdx.x;
int bRow = t * TILE_SIZE + threadIdx.y;
As[threadIdx.y][threadIdx.x] = (row < M && aCol < K)
? A[row * K + aCol] : 0.0f;
Bs[threadIdx.y][threadIdx.x] = (bRow < K && col < N)
? B[bRow * N + col] : 0.0f;
__syncthreads();
// 使用共享内存计算(无全局内存访问)
for (int k = 0; k < TILE_SIZE; k++) {
sum += As[threadIdx.y][k] * Bs[k][threadIdx.x];
}
__syncthreads();
}
if (row < M && col < N) {
C[row * N + col] = sum;
}
}
为什么分块有效?
- 不分块:每个元素从 HBM 读取 K 次,总数据搬运 = MNK
- 分块后:每个 Tile 从 HBM 读 1 次,在 Shared Memory 中被复用 TILE_SIZE 次
- 数据复用率提升 TILE_SIZE 倍
更高级的优化方向:
| 优化技术 | 效果 | 说明 |
|---|---|---|
向量化加载 (float4) | 提升 HBM 带宽利用率 | 一条指令加载 16 字节 |
| 寄存器分块 | 每线程计算多个输出元素 | 减少 Shared Memory 访问次数 |
| 双缓冲(Double Buffering) | 加载与计算重叠 | 一个 Tile 计算时预加载下一个 |
| Tensor Core (WMMA/CUTLASS) | 数量级提升 | 硬件矩阵乘加速 |
实际工程中,一般直接使用 cuBLAS(NVIDIA 官方高度优化的 BLAS 库)或 CUTLASS(可定制的模板库):
#include <cublas_v2.h>
cublasHandle_t handle;
cublasCreate(&handle);
float alpha = 1.0f, beta = 0.0f;
// C = alpha * A * B + beta * C
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N,
N, M, K, &alpha, d_B, N, d_A, K, &beta, d_C, N);
cublasDestroy(handle);
6.3 Softmax
Softmax 是 Attention 中的核心操作。高效的 Softmax 实现需要解决数值稳定性和并行归约两个问题。
数学公式
减去 max(x) 是为了数值稳定性,防止 exp 溢出。
朴素实现(两趟)
__global__ void softmaxNaive(float* input, float* output, int N) {
// 假设一个 Block 处理一行
__shared__ float smem[256];
int tid = threadIdx.x;
// 1. 求 max(Reduce 操作)
float maxVal = -FLT_MAX;
for (int i = tid; i < N; i += blockDim.x) {
maxVal = fmaxf(maxVal, input[i]);
}
smem[tid] = maxVal;
__syncthreads();
// ... 树形归约求全局 max ...
float globalMax = smem[0];
__syncthreads();
// 2. 求 exp 之和(Reduce 操作)
float sumExp = 0.0f;
for (int i = tid; i < N; i += blockDim.x) {
sumExp += expf(input[i] - globalMax);
}
smem[tid] = sumExp;
__syncthreads();
// ... 树形归约求 sum ...
float globalSum = smem[0];
__syncthreads();
// 3. 计算 softmax
for (int i = tid; i < N; i += blockDim.x) {
output[i] = expf(input[i] - globalMax) / globalSum;
}
}
Online Softmax(一趟)
NVIDIA 提出的 Online Normalizer Calculation 方法,可以在一趟遍历中同时维护 max 和 sum,减少一次全局内存读取:
// 核心思想:在线更新 max 和 sum
float m = -FLT_MAX; // 当前 max
float d = 0.0f; // 当前 sum(exp(x - m))
for (int i = tid; i < N; i += blockDim.x) {
float x = input[i];
float m_new = fmaxf(m, x);
// 关键:旧的 sum 需要用校正因子调整
d = d * expf(m - m_new) + expf(x - m_new);
m = m_new;
}
// 最终:softmax(x_i) = exp(x_i - m) / d
这个技巧是 FlashAttention 的数学基础之一。
6.4 算子融合(Kernel Fusion)
算子融合是将多个小操作合并为一个 kernel 执行,避免中间结果写回全局内存。就像做菜时一次洗好所有菜,而不是做一道菜洗一次——每次写回全局内存再读回来,就像反复跑去水龙头前洗菜,白白浪费时间在”搬运”上。
未融合:
kernel1: A = input + bias → 写回 HBM
kernel2: B = ReLU(A) → 读 A 从 HBM,写 B 回 HBM
kernel3: output = LayerNorm(B) → 读 B 从 HBM
融合后:
fused_kernel: output = LayerNorm(ReLU(input + bias))
→ 只读一次 input,中间结果在寄存器/共享内存中流转
对于 memory bound 的逐元素操作(ReLU、Add、LayerNorm),融合可以获得数倍加速,因为瓶颈在 HBM 读写而不是计算。
7. Attention 算子
Attention 是 Transformer 的核心操作,也是大模型计算量和显存占用的主要来源。理解 Attention 算子的优化是 AI Infra 的必修课。
7.1 标准 Attention 的问题
标准 Attention 的计算公式:
计算流程中需要存储完整的 QK^T 矩阵(大小为 seq_len x seq_len),对于长序列场景,这个矩阵巨大。以 seq_len = 8192、batch = 32 为例:
QK^T 矩阵大小 = 32 * 128 * 8192 * 8192 * 2 bytes (FP16) ≈ 128 GB
这远超单卡 80GB 显存。即使显存够用,反复在 HBM 和 SRAM 之间搬运这个巨大矩阵也会严重拖慢速度。
7.2 FlashAttention
FlashAttention 的核心思想:通过 Tiling(分块)避免在 HBM 中存储完整的 QK^T 矩阵,将所有中间计算保持在 Shared Memory 中。
标准 Attention:
Q, K → QK^T (写 HBM) → softmax (读/写 HBM) → × V → output
↑ 中间矩阵 O(N^2) 存在 HBM,大量读写
FlashAttention:
对 Q 分块 → 每块与 K, V 的所有块做 Attention → 用 Online Softmax 拼接结果
↑ 中间矩阵只在 SRAM 中,不写回 HBM
关键技术:
- Tiling:将 Q、K、V 分成小块,每块能装进 Shared Memory
- Online Softmax:在分块计算中正确维护 softmax 的全局 max 和 sum
- 重计算(Recomputation):反向传播时不存储中间 Attention 矩阵,而是重新计算(用计算换显存)
IO 复杂度对比:
| 方法 | HBM 访问量 | 额外显存 |
|---|---|---|
| 标准 Attention | O(N^2 * d) | O(N^2) |
| FlashAttention | O(N^2 * d^2 / SRAM_SIZE) | O(N) |
对于 d=128、SRAM=192KB 的典型配置,FlashAttention 的 HBM 访问量减少 ~8 倍。
7.3 FlashAttention V2
V2 在 V1 基础上进一步优化了并行策略:
- 前向传播:在序列长度维度(而非 batch/head 维度)并行,提升长序列效率
- 反向传播:减少非矩阵乘法操作的比例,更好地利用 Tensor Core
- Block 划分:Q 和 K/V 用不同的 Block 大小,更适配硬件
实测 V2 比 V1 快 ~2 倍,达到 A100 理论峰值的 50-73%。
7.4 FlashAttention-3
针对 Hopper 架构(H100)的进一步优化:
- 利用 TMA(Tensor Memory Accelerator):硬件加速的异步数据搬运
- WGMMA 指令:Warp Group 级别的矩阵乘加速
- Ping-Pong 流水线:生产者-消费者模型,搬数据和算数据完全重叠
7.5 Flash-Decoding
FlashAttention 主要优化 Prefill 阶段(Q 矩阵很大)。Decode 阶段 Q 只有一个 token,瓶颈不同。
Flash-Decoding 的核心思想:将 KV Cache 沿序列维度分割,多个 Block 并行计算 Attention,最后归约合并。
标准 Decode Attention:
1 个 Block 处理整个 KV Cache → 并行度不足
Flash-Decoding:
Block 0: Q × K[0:L/4]^T → partial_output_0
Block 1: Q × K[L/4:L/2]^T → partial_output_1
Block 2: Q × K[L/2:3L/4]^T → partial_output_2
Block 3: Q × K[3L/4:L]^T → partial_output_3
→ 归约合并 partial outputs
7.6 FlashInfer
FlashInfer 是一个面向 Serving 场景的可定制 Attention 引擎:
- 支持 PagedAttention(vLLM 风格的分页 KV Cache)
- 支持多种 KV 布局(连续、分页、分块)的可组合格式
- 支持 KV Cache 量化(FP8、INT4)
- 支持 Prefill 和 Decode 的统一接口
7.7 PagedAttention
vLLM 提出的 PagedAttention 将操作系统的虚拟内存分页思想引入 KV Cache 管理:
- KV Cache 不再要求连续内存,而是分成固定大小的”页”
- 页可以按需分配和回收,消除内存碎片
- 不同请求可以共享相同的 KV Cache 页(如共享的 system prompt)
8. AI 编译器
手写 CUDA kernel 门槛高、调试难。AI 编译器正在降低高效 GPU 编程的门槛。
8.1 Triton
Triton 是 OpenAI 开源的 GPU 编程语言,使用 Python 语法编写 GPU kernel,编译器自动处理内存合并、共享内存管理、Warp 调度等底层细节。
Triton vs CUDA 对比:以向量加法为例
import triton
import triton.language as tl
import torch
@triton.jit
def add_kernel(
x_ptr, y_ptr, output_ptr,
n_elements,
BLOCK_SIZE: tl.constexpr,
):
# 计算当前 Block 处理的元素范围
pid = tl.program_id(0)
offsets = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
# 加载、计算、存储
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
# 调用
def add(x: torch.Tensor, y: torch.Tensor):
output = torch.empty_like(x)
n = x.numel()
grid = lambda meta: (triton.cdiv(n, meta['BLOCK_SIZE']),)
add_kernel[grid](x, y, output, n, BLOCK_SIZE=1024)
return output
# 使用
x = torch.randn(1000000, device='cuda')
y = torch.randn(1000000, device='cuda')
result = add(x, y)
Triton 的 Softmax 实现
@triton.jit
def softmax_kernel(
input_ptr, output_ptr,
n_cols,
input_row_stride, output_row_stride,
BLOCK_SIZE: tl.constexpr,
):
row_idx = tl.program_id(0)
row_start = row_idx * input_row_stride
col_offsets = tl.arange(0, BLOCK_SIZE)
mask = col_offsets < n_cols
# 加载一行
row = tl.load(input_ptr + row_start + col_offsets, mask=mask, other=-float('inf'))
# 数值稳定的 softmax
row_max = tl.max(row, axis=0)
numerator = tl.exp(row - row_max)
denominator = tl.sum(numerator, axis=0)
result = numerator / denominator
# 写回
tl.store(output_ptr + row_idx * output_row_stride + col_offsets, result, mask=mask)
Triton 的优势:
- Python 语法,学习曲线平缓
- 编译器自动处理内存合并、共享内存 Tiling、Warp 调度
- 性能可以达到手写 CUDA 的 80-95%
- FlashAttention 的原始实现就使用了 Triton
8.2 torch.compile
PyTorch 2.x 引入了 torch.compile,可以自动将 PyTorch 代码编译为高效的 GPU 代码:
import torch
@torch.compile
def fused_gelu(x):
return x * 0.5 * (1.0 + torch.tanh(0.7978845608 * (x + 0.044715 * x ** 3)))
# 首次调用触发编译,后续调用使用编译结果
output = fused_gelu(input_tensor)
torch.compile 的后端链路:
PyTorch 代码 → TorchDynamo(图捕获)→ TorchInductor(代码生成)→ Triton kernel
Graph Break:当 torch.compile 遇到无法编译的操作(如 Python 副作用、动态控制流),会”打断”计算图,降低优化效果。排查方法:
TORCH_LOGS="graph_breaks" python your_script.py
8.3 TVM / XLA
| 编译器 | 核心特点 | 适用场景 |
|---|---|---|
| TVM (Apache) | 可移植的张量编译器,自动搜索最优配置 | 需要跨硬件平台的推理优化 |
| XLA (Google) | JAX/TensorFlow 的 JIT 编译器 | JAX 生态,TPU 优化 |
| Triton (OpenAI) | Python 化的 GPU 编程 | 自定义算子开发 |
| TorchInductor | PyTorch 原生编译器 | PyTorch 生态的整图优化 |
9. 性能分析工具
写出能跑的 kernel 只是第一步,知道瓶颈在哪 才是优化的关键。
9.1 Nsight Compute(Kernel 级分析)
# 对指定 kernel 做详细分析
ncu --set full -o profile ./your_app
# 关注特定指标
ncu --metrics \
sm__throughput.avg.pct_of_peak_sustained_active,\
dram__throughput.avg.pct_of_peak_sustained_active \
./your_app
核心指标:
| 指标 | 含义 | 目标 |
|---|---|---|
| Compute (SM) Throughput | 计算单元利用率 | Compute bound 时应 >70% |
| Memory Throughput | HBM 带宽利用率 | Memory bound 时应 >70% |
| Achieved Occupancy | 活跃 Warp 占比 | >25%(非越高越好) |
| Warp Execution Efficiency | 分支发散程度 | >85% |
| L2 Hit Rate | L2 缓存命中率 | >70% |
| Shared Memory Bank Conflicts | Bank 冲突次数 | 0 |
9.2 Nsight Systems(系统级分析)
nsys profile -o timeline ./your_app
用来分析全局时序:
- Kernel 之间是否有 CPU 端空隙(launch overhead)
- 数据传输是否与计算重叠
- 多 Stream 是否真正并发
- 瓶颈在 Host 端还是 Device 端
9.3 编译器输出
# 查看寄存器和共享内存使用
nvcc -Xptxas -v kernel.cu
# 查看 PTX 中间代码
nvcc --ptx kernel.cu
# 查看 SASS 汇编(最终机器码)
cuobjdump -sass kernel
10. 自我检验清单
完成本文学习后,你应该能够:
- 能解释 Grid → Block → Thread 的三层结构,并根据数据规模配置合适的 Block 大小
- 能区分 GPU 的 5 种内存类型(寄存器、Local、Shared、Global、Constant),并说明各自的作用域和生命周期
- 能解释什么是 Warp、合并访存(Coalesced Access)和 Bank Conflict
- 能编写一个基本的 CUDA Kernel(如向量加法),并用 nvcc 编译运行
- 能独立编写一个正确的 Reduce kernel,并做至少两轮优化(Warp Shuffle + 多元素累加)
- 能实现 Tiled GEMM 并解释为什么 Tiling 能减少全局内存访问
- 能写出 Online Softmax 的算法流程,解释为什么它比 Naive Softmax 更好
- 能解释 FlashAttention 的核心思想(Tiling + Online Softmax + 不存中间矩阵)
- 能使用 Triton 编写一个简单的 kernel(如向量加法或 Softmax),并与 PyTorch 结果对比
- 能用 Nsight Compute 分析自己写的 kernel,判断是 memory bound 还是 compute bound
📚 参考资料
- NVIDIA CUDA C++ Programming Guide
- NVIDIA CUDA C++ Best Practices Guide
- Nsight Compute Documentation
- Nsight Systems User Guide
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
- Flash-Decoding for long-context inference - Stanford CRFM
- FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
- FlashInfer - GitHub
- vLLM: Efficient Memory Management for Large Language Model Serving with PagedAttention
- Online normalizer calculation for softmax
- Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations
- Triton Tutorials
- CUTLASS - GitHub
- 猛猿:图解FlashAttention V1/V2 系列
- 方佳瑞:深入浅出理解PagedAttention CUDA实现
- 猛猿:从啥也不会到CUDA GEMM优化