从零理解 AI Infra
全面介绍 AI Infra的定义、技术栈全貌和核心组件,帮助你建立对 AI Infra 领域的整体认知
AI Infra 是让大模型从实验室走向生产环境的技术底座。本文将从零开始,帮你建立对这个领域的全景认知。
📑 目录
- 1. 什么是 AI Infra
- 2. 为什么 AI Infra 越来越重要
- 3. AI Infra 技术栈全景
- 4. 硬件层:算力基础
- 5. 系统软件层:让硬件跑起来
- 6. 训练系统:教会模型思考
- 7. 推理系统:让模型服务用户
- 8. 性能工程:榨干每一分算力
- 9. AI Infra 工程师的能力模型
- 总结
1. 什么是 AI Infra
打个比方:如果大模型是一辆高性能赛车,那么 AI Infra 就是赛道、加油站、维修团队和整套后勤保障系统——没有它们,赛车哪儿也去不了。
用更正式的语言来说,AI Infra(AI Infrastructure,AI 基础设施) 是指支撑 AI 模型训练、推理和服务的全套技术体系,涵盖从底层硬件到上层调度编排的完整技术栈。
它要解决的核心问题只有一个:如何高效、可靠、低成本地运行 AI 工作负载。
1.1 AI Infra 的边界
AI Infra 和 AI 算法是两个不同但紧密协作的领域:
| 📊 维度 | 🧠 AI 算法 | 🔧 AI Infra |
|---|---|---|
| 核心关注 | 模型效果(准确率、生成质量) | 运行效率(吞吐、延迟、成本) |
| 典型工作 | 设计网络结构、调参、训练策略 | GPU 编程、分布式训练、推理部署 |
| 优化目标 | Loss 更低、效果更好 | 速度更快、显存更省、扩展性更强 |
| 代表技术 | Transformer、RLHF、MoE | CUDA、NCCL、vLLM、FlashAttention |
💡 提示:两者的交叉地带越来越多——比如 FlashAttention 既是算法创新(IO 感知的精确注意力),也是 Infra 优化(CUDA Kernel 实现)。理解 AI Infra 会让你对算法的工程落地有更深的认识。
2. 为什么 AI Infra 越来越重要
2.1 大模型时代的算力饥渴
GPT-3 的训练需要约 3640 PF-days(即 3640 petaflop/s 的算力运行一天),而 GPT-4 的训练算力需求估计是 GPT-3 的数十倍以上。Llama 3 405B 的训练使用了 16384 张 H100 GPU,持续训练数周。
这意味着:
- 单张 GPU 的算力远远不够,必须组建大规模集群
- 多卡之间的通信开销可能比计算本身还耗时
- 一次训练动辄花费数百万美元,效率提升 10% 就是巨大的成本节省
2.2 推理成本成为瓶颈
训练是一次性投入,但推理是持续性支出。当一个大模型被数百万用户同时使用时:
- 每个请求都需要 GPU 资源来做前向计算
- 用户期望的响应延迟在毫秒到秒级
- 推理成本可能占到 AI 服务总成本的 80% 以上
📌 关键点:推理优化(更高吞吐、更低延迟、更少显存)直接决定了 AI 产品的商业可行性。
2.3 人才缺口巨大
目前行业对 AI Infra 工程师的需求远超供给。原因很简单:这个领域需要同时理解硬件架构、系统编程、分布式系统和 AI 算法,跨学科的知识壁垒很高,但一旦掌握,价值也非常大。
3. AI Infra 技术栈全景
AI Infra 可以按层次划分为四层,从底向上依次是:
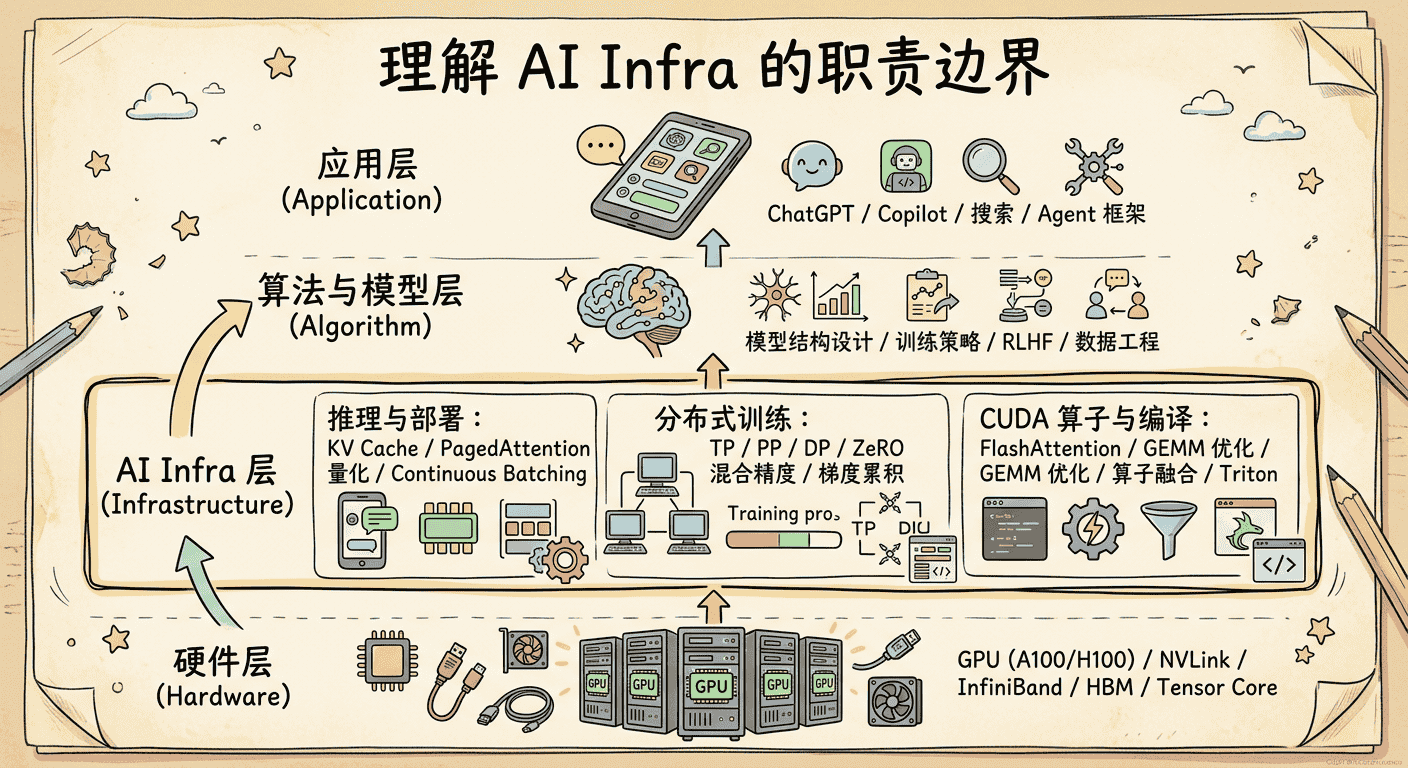
每一层都有独特的技术挑战和优化空间。接下来我们逐层展开。
4. 硬件层:算力基础
4.1 GPU:AI 计算的核心引擎
为什么深度学习用 GPU 而不是 CPU?因为深度学习的核心运算是矩阵乘法,而矩阵乘法天然适合并行——一张 GPU 拥有数千个计算核心,可以同时处理大量元素的运算。
以 NVIDIA 的 GPU 为例,核心架构演进如下:
| 架构 | 年份 | 代表产品 | 关键特性 |
|---|---|---|---|
| Volta | 2017 | V100 | 首次引入 Tensor Core |
| Ampere | 2020 | A100 | 支持 TF32/BF16,MIG 多实例 |
| Hopper | 2022 | H100 | FP8 支持,Transformer Engine |
| Blackwell | 2024 | B200 | 第二代 Transformer Engine,FP4 |
🔑 核心概念:Tensor Core 是 NVIDIA GPU 中专门为矩阵运算设计的硬件单元。以 H100 为例,其 FP16 Tensor Core 算力高达 989 TFLOPS,远超普通 CUDA Core 的算力。
4.2 互联技术:多卡协同的关键
单卡算力有上限,多卡协同训练就需要高速互联:
- NVLink:GPU 之间的直连通道。H100 的 NVLink 4.0 提供 900 GB/s 的双向带宽,远超 PCIe 5.0 的 128 GB/s
- NVSwitch:连接同一节点内多张 GPU 的交换芯片,实现全对全互联
- InfiniBand:跨节点的高速网络。NVIDIA NDR InfiniBand 提供 400 Gbps 带宽,且延迟极低(约 1 微秒级)
💡 提示:通信带宽往往是大规模训练的第一个瓶颈。当你发现训练扩展效率不高时,首先应该排查的就是通信。
4.3 显存:HBM 的重要性
GPU 的显存带宽直接影响模型的运行效率。现代 AI GPU 普遍采用 HBM(High Bandwidth Memory):
- H100 SXM 配备 80GB HBM3,带宽 3.35 TB/s
- A100 配备 80GB HBM2e,带宽 2.0 TB/s
很多 AI 工作负载(尤其是推理)是内存带宽瓶颈而非计算瓶颈,这意味着显存带宽的提升有时比算力提升更重要。
5. 系统软件层:让硬件跑起来
5.1 CUDA:GPU 编程的基础语言
CUDA 是 NVIDIA 推出的 GPU 并行计算平台和编程模型。可以把它理解为”GPU 上的编程语言”——你通过 CUDA 告诉 GPU 要做什么运算、怎么调度线程。
一个简单的 CUDA 向量加法示例:
__global__ void vectorAdd(float* a, float* b, float* c, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
c[idx] = a[idx] + b[idx];
}
}
// 启动 Kernel:256 个线程为一个 Block
int blocks = (n + 255) / 256;
vectorAdd<<<blocks, 256>>>(d_a, d_b, d_c, n);
CUDA 编程中最核心的概念是线程层级:
- Thread:最小的执行单元
- Block:一组线程,共享 Shared Memory
- Grid:所有 Block 的集合
5.2 通信库:NCCL
当多张 GPU 需要协同计算时,需要高效的通信原语。NCCL(NVIDIA Collective Communications Library)提供了 AllReduce、AllGather、ReduceScatter 等集合通信操作,是分布式训练的通信基础。
5.3 算子库
高性能的基础运算不需要从头写 CUDA,NVIDIA 提供了丰富的算子库:
- cuBLAS:矩阵乘法(GEMM)
- cuDNN:卷积、池化、归一化等深度学习算子
- cuFFT:快速傅里叶变换
6. 训练系统:教会模型思考
6.1 为什么需要分布式训练
以 Llama 3 405B 为例,模型参数量 4050 亿,仅存储参数就需要约 810 GB(FP16),远超单张 GPU 的显存容量。更不用说训练时还需要保存梯度、优化器状态等中间数据,总显存需求是参数量的 10-20 倍。
所以,大模型训练必须使用多卡甚至多节点。
6.2 并行策略
分布式训练有三种基本并行方式,就像一个工厂里的三种分工方法:
数据并行(Data Parallelism):每张 GPU 持有完整的模型副本,但各自处理不同的数据。训练完成后同步梯度。就像同一道菜谱,多个厨师各做一份,最后汇总味道反馈。
- 代表技术:PyTorch DDP、FSDP(分片版数据并行)
- 适用场景:模型能放进单卡显存
模型并行(Tensor Parallelism):把模型的每一层”切开”,分散到多张 GPU 上。就像一张大桌子太重了,拆成几块分别搬。
- 代表技术:Megatron-LM
- 适用场景:单层参数量大(如大模型的 Attention 和 FFN 层)
流水线并行(Pipeline Parallelism):把模型按层分段,不同段放在不同 GPU 上,数据像流水线一样依次通过各段。
- 代表技术:GPipe、PipeDream
- 适用场景:模型层数多,适合按深度切分
⚠️ 注意:实际的大规模训练通常结合三种并行(称为 3D 并行),需要根据模型大小、集群规模和网络拓扑仔细调参。
6.3 关键框架
| 框架 | 开发者 | 核心特性 |
|---|---|---|
| PyTorch DDP | Meta | 原生数据并行,简单易用 |
| PyTorch FSDP | Meta | 参数分片的数据并行,省显存 |
| DeepSpeed | Microsoft | ZeRO 优化器,灵活的并行组合 |
| Megatron-LM | NVIDIA | 高性能的张量并行和流水线并行 |
7. 推理系统:让模型服务用户
7.1 推理的核心挑战
训练时,追求的是吞吐量(单位时间处理更多样本);推理时,既要高吞吐又要低延迟。
大模型推理有一个独特的特点:它是自回归的——每次只生成一个 token,且每个 token 的生成都依赖之前的所有 token。这导致推理过程天然是串行的,优化难度很大。
7.2 关键优化技术
KV Cache:在自回归生成中,每个 token 的 Attention 计算需要用到之前所有 token 的 Key 和 Value。把它们缓存起来,避免重复计算。代价是显存占用会随序列长度线性增长。
PagedAttention:传统的 KV Cache 为每个请求预分配连续的显存块,就像餐厅给每桌客人预留固定大小的区域,不管实际用多少。PagedAttention 借鉴了操作系统虚拟内存分页的思想,将 KV Cache 分成固定大小的 Page,按需分配,把显存利用率从约 60% 提升到接近 100%。
量化:用更低精度的数据类型(FP8、INT8、INT4)表示模型参数,减少显存占用和计算量。例如 FP16 → INT8 量化可以将模型体积减半,推理速度提升 1.5-2 倍,精度损失通常在可接受范围内。
7.3 主流推理引擎
| 引擎 | 核心技术 | 特点 |
|---|---|---|
| vLLM | PagedAttention | 开源标杆,社区活跃 |
| SGLang | RadixAttention | 前缀共享优化,适合多轮对话 |
| TensorRT-LLM | NVIDIA 自研 Kernel | 极致性能,深度绑定 NVIDIA 硬件 |
8. 性能工程:榨干每一分算力
8.1 为什么需要性能分析
写出能跑的 CUDA Kernel 只是第一步,写出跑得快的 Kernel 才是核心价值。性能分析(Profiling)帮你找到瓶颈在哪里——是计算不够快?还是数据搬运太慢?还是线程在等待?
8.2 Roofline 模型
Roofline 模型是性能分析的核心思维框架。它把算子分为两类:
- 计算瓶颈(Compute-bound):算力不够用,如大矩阵乘法
- 访存瓶颈(Memory-bound):数据搬运速度跟不上计算速度,如逐元素操作
判断依据是算术强度(Arithmetic Intensity):每搬运 1 字节数据能做多少次浮点运算。
当算术强度低于硬件的 “拐点” 时,算子受限于内存带宽;反之受限于计算能力。
8.3 核心 Profiling 工具
- Nsight Systems:系统级分析,看 CPU/GPU 的时间线、Kernel 调度、通信开销——帮你找到”哪里慢”
- Nsight Compute:Kernel 级分析,看单个 Kernel 内部的计算效率、内存吞吐、Warp 占用率——帮你找到”为什么慢”
💡 提示:先用 Nsight Systems 定位热点 Kernel,再用 Nsight Compute 深入分析该 Kernel 的瓶颈,是最高效的性能优化工作流。
9. AI Infra 工程师的能力模型
如果你想进入这个领域,需要构建以下几层能力:
9.1 基础层
- C/C++ 编程:CUDA 编程基于 C/C++,需要熟练掌握指针、内存管理
- 计算机体系结构:理解 CPU/GPU 的存储层级(寄存器 → L1 → L2 → HBM → 主存)
- Linux 系统:大部分 AI Infra 工作在 Linux 环境下
9.2 核心层
- CUDA 编程:Thread/Block/Grid 模型、Shared Memory、Warp 调度
- 分布式系统基础:通信原语(AllReduce、AllGather)、一致性、容错
- PyTorch 内部机制:Autograd、Module、分布式训练 API
9.3 进阶层
- 算子优化:Tiling 策略、Memory Coalescing、Bank Conflict 消除
- 并行策略设计:根据模型和硬件特征选择最优的并行组合
- 推理引擎原理:调度器设计、KV Cache 管理、量化算法
📌 关键点:AI Infra 是一个”既需要广度又需要深度”的领域。广度让你理解系统全貌,深度让你解决实际的性能问题。建议先建立全景认知(也就是这篇文章的目标),再选择一个方向深入。
📝 总结
- AI Infra 是支撑大模型训练、推理和服务的完整技术体系,从 GPU 硬件到调度编排
- 大模型时代,AI Infra 的重要性空前提升——训练需要大规模集群,推理需要极致优化
- 技术栈分为五层:硬件层 → 系统软件层 → 训练系统层 → 推理系统层 → 应用与调度层
- 核心技能包括 CUDA 编程、分布式训练、推理优化和性能分析
- 这是一个人才缺口巨大、技术壁垒高但回报丰厚的领域
🎯 自我检验清单
- 能用自己的话解释什么是 AI Infra 以及它和 AI 算法的区别
- 能画出 AI Infra 技术栈的分层架构(硬件层到应用层)
- 能说出 Tensor Core、NVLink、HBM 分别解决什么问题
- 能区分数据并行、模型并行和流水线并行的适用场景
- 能解释 KV Cache 和 PagedAttention 的基本原理
- 能说出 Roofline 模型中计算瓶颈和访存瓶颈的判断依据
- 能描述 Nsight Systems 和 Nsight Compute 的定位差异
📚 参考资料
- NVIDIA H100 Tensor Core GPU Architecture
- NVIDIA CUDA C++ Programming Guide
- PyTorch Distributed Overview
- vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
- DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters
- Roofline: An Insightful Visual Performance Model