3.7 Transformer Decoder Block完整解析
大语言模型的核心计算单元是 Transformer Decoder Block
大语言模型的核心计算单元是 Transformer Decoder Block。无论你在做 CUDA 算子优化、分布式训练还是推理部署,最终操作的对象都是这个 Block 里面的矩阵乘法、归一化和注意力计算。本文将这个 Block 彻底拆开,从架构选型的历史原因讲起,逐步深入到因果掩码的实现、完整的 PyTorch 代码、参数量与计算量的手算方法,最后落地到显存规划的工程实践。目标是读完之后,你能拿着纸笔算清楚任意一个开源模型”能不能装进某张卡”。
📑 目录
- 1. 架构选型:为什么 Decoder-only 成为主流
- 2. Decoder Block 完整数据流
- 3. Causal Mask:因果掩码详解
- 4. PyTorch 实现:从零搭建 Decoder Block
- 5. 主流模型维度配置对比
- 6. 参数量手算教学
- 7. 计算量(FLOPs)估算
- 8. 显存规划详解
- 9. 主流开源模型架构对比
- 自我检验清单
- 参考资料
1. 架构选型:为什么 Decoder-only 成为主流
1.1 三种 Transformer 架构回顾
2017 年的原始论文 “Attention Is All You Need” 提出的是一个 Encoder-Decoder 架构:Encoder 负责理解输入,Decoder 负责生成输出。此后演化出三条路线:
| 架构 | 代表模型 | 核心特点 | 典型任务 |
|---|---|---|---|
| Encoder-only | BERT, RoBERTa | 双向注意力,看到完整上下文 | 分类、NER、句子相似度 |
| Encoder-Decoder | T5, BART, mBART | Encoder 双向理解,Decoder 自回归生成 | 翻译、摘要、问答 |
| Decoder-only | GPT 系列, LLaMA, Mistral, Qwen | 单向因果注意力,自回归生成 | 通用文本生成、对话、推理 |
打个比方:Encoder-only 像一个阅读理解专家,擅长”读懂”但不会”写作”;Encoder-Decoder 像一个翻译官,需要先完整理解原文再逐句翻译;Decoder-only 则像一个即兴演讲者,边想边说,每句话只基于前面已经说过的内容。
1.2 Decoder-only 胜出的原因
进入大模型时代后,Decoder-only 几乎一统天下。这并非巧合,背后有多重原因:
✅ 统一的训练范式。Decoder-only 的训练目标极其简单——预测下一个 token。无论输入是什么语言、什么任务,训练信号都是统一的。相比之下,Encoder-Decoder 需要设计”输入-输出”对,数据构造更复杂。当你有数万亿 token 的无标注文本时,“预测下一个词”是最自然、最高效的利用方式。
✅ 规模扩展(Scaling)更简单。Decoder-only 架构只有一种 Block 不断堆叠,想扩大模型只需增加层数或隐藏维度。Encoder-Decoder 架构需要同时扩展两个组件,还得平衡二者的比例,调参空间更大。OpenAI 的 Scaling Laws 研究表明,在固定计算预算下,Decoder-only 架构的参数效率与 Encoder-Decoder 基本相当,但工程复杂度低得多。
✅ 推理效率的优势。Decoder-only 架构在推理时只需维护一套 KV Cache,而 Encoder-Decoder 需要维护 Encoder 侧的输出和 Decoder 侧的 KV Cache 两套数据。对于长上下文的对话场景,简单的 KV Cache 管理意味着更高的系统吞吐量。
✅ 涌现能力的经验观察。实践中发现,当模型参数量超过一定阈值后,Decoder-only 架构在 few-shot 和 zero-shot 场景下展现出显著的涌现能力(如 chain-of-thought 推理)。这些能力在 Encoder-only 和 Encoder-Decoder 架构上不那么明显。
✳️ 总结一句话:Decoder-only 在大规模场景下,以最简洁的架构获得了最好的通用能力,同时对工程系统最友好。 从 GPT-3 到 LLaMA,再到 Mistral、Qwen、DeepSeek,全部采用这一路线。
2. Decoder Block 完整数据流
一个 Pre-Norm Decoder-only Block 内部的数据流转可以用下面的图来表示。
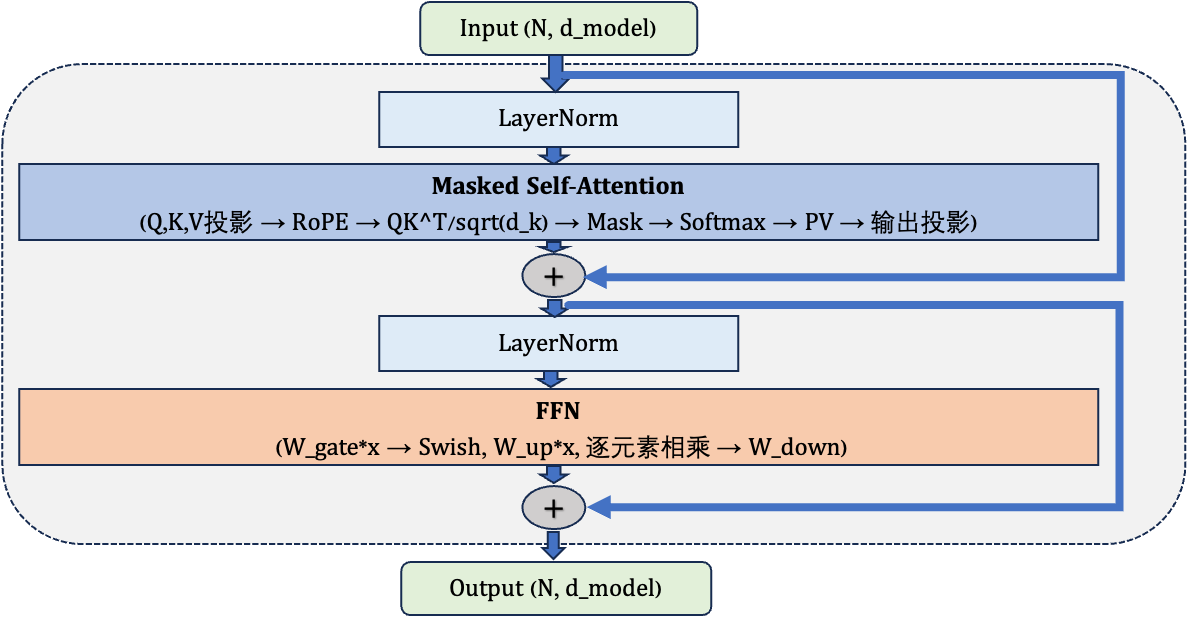
几个值得注意的细节:
🍎 RMSNorm 而非 LayerNorm。LLaMA 系列及后续大多数模型使用 RMSNorm(Root Mean Square Normalization),省去了减均值的步骤,只保留除以均方根的操作。计算更简单,效果相当。
🍎 RoPE 只作用于 Q 和 K。旋转位置编码的作用是让 Q 和 K 的内积包含相对位置信息,V 不需要旋转,因为 V 承载的是”内容信息”而非”位置匹配信号”。
🍎 Pre-Norm 的残差路径是干净的。注意图中两条残差路径都是从 Add 节点直接拉过来的,中间没有经过任何变换。这保证了梯度可以无损地沿残差路径回传,是深层模型训练稳定的关键。
3. Causal Mask:因果掩码详解
3.1 为什么需要因果掩码
Decoder-only 模型的训练目标是”给定前面的 token,预测下一个 token”。这意味着在计算第 i 个 token 的 Attention 时,它只能看到位置 0 到 i 的信息,不能”偷看”位置 i+1 及之后的 token——否则预测任务就变成了”开卷考试”,模型学不到任何东西。
这个约束在自然语言生成中是合理的:你在说第五个字的时候,确实不知道第六个字会是什么。模型必须遵守同样的因果顺序。
在训练时,为了效率,我们把整个序列一次性送入模型并行计算(而非逐 token 送入)。但并行计算意味着所有 token 的 Attention 是同时算的,如果不加限制,每个 token 都会”看到”整个序列。因果掩码(Causal Mask)就是用来在并行计算的同时强制执行”只能看过去”的约束。
3.2 掩码矩阵的可视化
假设序列长度为 5,Attention 分数矩阵 S 的形状是 (5, 5)。S[i][j] 表示第 i 个 token 对第 j 个 token 的原始注意力分数。因果掩码要求:当 j > i(即 j 在 i 后面)时,S[i][j] 必须被屏蔽。
掩码矩阵 M 长这样(0 表示保留,-inf 表示屏蔽):
Token: t0 t1 t2 t3 t4
t0 [ 0 -inf -inf -inf -inf ]
t1 [ 0 0 -inf -inf -inf ]
t2 [ 0 0 0 -inf -inf ]
t3 [ 0 0 0 0 -inf ]
t4 [ 0 0 0 0 0 ]
将 M 加到 S 上之后,被屏蔽的位置变成负无穷。接下来做 softmax 时,,这些位置的注意力权重就变成了零。
用另一种直观的方式表示——哪些位置能被”看到”(用 1 表示可见,0 表示不可见):
Token: t0 t1 t2 t3 t4
t0 [ 1 0 0 0 0 ] t0 只能看自己
t1 [ 1 1 0 0 0 ] t1 能看 t0 和自己
t2 [ 1 1 1 0 0 ] t2 能看 t0, t1 和自己
t3 [ 1 1 1 1 0 ] t3 能看前面所有和自己
t4 [ 1 1 1 1 1 ] t4 能看全部
这是一个下三角矩阵,因此因果掩码也被称为”下三角掩码”或”上三角掩码”(取决于你说的是保留区域还是屏蔽区域)。
3.3 实现方式
在代码层面,因果掩码的实现非常简洁:
import torch
def create_causal_mask(seq_len, device='cuda'):
"""创建因果掩码:上三角区域为 -inf,其余为 0"""
# torch.triu 取上三角,diagonal=1 表示从主对角线上方一行开始
mask = torch.triu(
torch.full((seq_len, seq_len), float('-inf'), device=device),
diagonal=1
)
return mask
# 示例:seq_len = 4
# tensor([[ 0., -inf, -inf, -inf],
# [ 0., 0., -inf, -inf],
# [ 0., 0., 0., -inf],
# [ 0., 0., 0., 0.]])
使用时直接加到 Attention 分数上:
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
scores = scores + create_causal_mask(seq_len, device=scores.device)
attn_weights = torch.softmax(scores, dim=-1)
在实际的高性能实现中(如 FlashAttention),因果掩码不是显式地构造一个 N x N 矩阵然后相加,而是在 tiled 计算过程中通过索引判断来跳过不需要计算的上三角区域,既节省显存又减少无效计算。
4. PyTorch 实现:从零搭建 Decoder Block
下面是一个完整的、可运行的 Transformer Decoder Block 实现,包含 Pre-Norm(RMSNorm)、Masked Multi-Head Attention(带 RoPE)、SwiGLU FFN 和残差连接。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class RMSNorm(nn.Module):
"""RMSNorm: 只做均方根归一化,省去减均值步骤"""
def __init__(self, d_model: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(d_model))
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x: (batch, seq_len, d_model)
rms = torch.sqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps)
return x / rms * self.weight
def precompute_rope_freqs(d_k: int, max_seq_len: int, theta: float = 10000.0):
"""预计算 RoPE 的旋转频率"""
# 频率: theta_i = 1 / (theta ^ (2i / d_k)), i = 0, 1, ..., d_k/2 - 1
freqs = 1.0 / (theta ** (torch.arange(0, d_k, 2).float() / d_k))
# 位置索引: 0, 1, ..., max_seq_len - 1
positions = torch.arange(max_seq_len).float()
# 外积: (max_seq_len, d_k // 2)
angles = torch.outer(positions, freqs)
# 返回 cos 和 sin,形状均为 (max_seq_len, d_k // 2)
return torch.cos(angles), torch.sin(angles)
def apply_rope(x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor):
"""
对 Q 或 K 施加旋转位置编码
x: (batch, seq_len, num_heads, d_k)
cos, sin: (seq_len, d_k // 2)
"""
seq_len = x.shape[1]
cos = cos[:seq_len].unsqueeze(0).unsqueeze(2) # (1, seq, 1, d_k//2)
sin = sin[:seq_len].unsqueeze(0).unsqueeze(2)
# 将 x 的最后一维拆成两半
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
# 旋转公式:(x1 * cos - x2 * sin, x1 * sin + x2 * cos)
rotated = torch.cat([x1 * cos - x2 * sin, x1 * sin + x2 * cos], dim=-1)
return rotated
class MaskedMultiHeadAttention(nn.Module):
"""带因果掩码的多头注意力"""
def __init__(self, d_model: int, num_heads: int):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_Q = nn.Linear(d_model, d_model, bias=False)
self.W_K = nn.Linear(d_model, d_model, bias=False)
self.W_V = nn.Linear(d_model, d_model, bias=False)
self.W_O = nn.Linear(d_model, d_model, bias=False)
def forward(self, x: torch.Tensor, rope_cos: torch.Tensor,
rope_sin: torch.Tensor) -> torch.Tensor:
batch, seq_len, _ = x.shape
# 线性投影
Q = self.W_Q(x) # (batch, seq, d_model)
K = self.W_K(x)
V = self.W_V(x)
# 切分为多头: (batch, seq, num_heads, d_k)
Q = Q.view(batch, seq_len, self.num_heads, self.d_k)
K = K.view(batch, seq_len, self.num_heads, self.d_k)
V = V.view(batch, seq_len, self.num_heads, self.d_k)
# 施加 RoPE(仅对 Q 和 K)
Q = apply_rope(Q, rope_cos, rope_sin)
K = apply_rope(K, rope_cos, rope_sin)
# 转置为 (batch, num_heads, seq, d_k) 便于批量矩阵乘
Q = Q.transpose(1, 2)
K = K.transpose(1, 2)
V = V.transpose(1, 2)
# 计算注意力分数: (batch, num_heads, seq, seq)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 因果掩码
causal_mask = torch.triu(
torch.full((seq_len, seq_len), float('-inf'), device=x.device),
diagonal=1
)
scores = scores + causal_mask.unsqueeze(0).unsqueeze(0)
# Softmax + 加权求和
attn_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, V) # (batch, heads, seq, d_k)
# 合并多头: (batch, seq, d_model)
output = output.transpose(1, 2).contiguous().view(batch, seq_len, -1)
# 输出投影
return self.W_O(output)
class SwiGLUFFN(nn.Module):
"""SwiGLU 前馈网络:三个线性层 + 门控激活"""
def __init__(self, d_model: int, ffn_dim: int):
super().__init__()
self.W_gate = nn.Linear(d_model, ffn_dim, bias=False)
self.W_up = nn.Linear(d_model, ffn_dim, bias=False)
self.W_down = nn.Linear(ffn_dim, d_model, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# gate 路径: 通过 SiLU (= Swish with beta=1) 激活
gate = F.silu(self.W_gate(x)) # (batch, seq, ffn_dim)
# up 路径: 线性变换,不加激活
up = self.W_up(x) # (batch, seq, ffn_dim)
# 门控相乘 + 降维
return self.W_down(gate * up) # (batch, seq, d_model)
class TransformerDecoderBlock(nn.Module):
"""完整的 Pre-Norm Transformer Decoder Block"""
def __init__(self, d_model: int, num_heads: int, ffn_dim: int,
norm_eps: float = 1e-6):
super().__init__()
self.norm1 = RMSNorm(d_model, eps=norm_eps)
self.attn = MaskedMultiHeadAttention(d_model, num_heads)
self.norm2 = RMSNorm(d_model, eps=norm_eps)
self.ffn = SwiGLUFFN(d_model, ffn_dim)
def forward(self, x: torch.Tensor, rope_cos: torch.Tensor,
rope_sin: torch.Tensor) -> torch.Tensor:
# 第一个子层: RMSNorm -> Masked MHA -> 残差
h = x + self.attn(self.norm1(x), rope_cos, rope_sin)
# 第二个子层: RMSNorm -> SwiGLU FFN -> 残差
out = h + self.ffn(self.norm2(h))
return out
# ---------- 验证:用 LLaMA-2-7B 配置实例化 ----------
if __name__ == "__main__":
d_model = 4096
num_heads = 32
ffn_dim = 11008
max_seq_len = 4096
d_k = d_model // num_heads # 128
block = TransformerDecoderBlock(d_model, num_heads, ffn_dim)
# 预计算 RoPE
rope_cos, rope_sin = precompute_rope_freqs(d_k, max_seq_len)
# 模拟输入: batch=2, seq_len=128
x = torch.randn(2, 128, d_model)
output = block(x, rope_cos, rope_sin)
print(f"Input shape: {x.shape}") # (2, 128, 4096)
print(f"Output shape: {output.shape}") # (2, 128, 4096)
# 统计参数量
total_params = sum(p.numel() for p in block.parameters())
print(f"Single block params: {total_params:,}") # ~201M
代码说明几个关键点:
- RMSNorm 只有一个可学习参数
weight(即 ),没有 bias。它对每个 token 的特征向量计算均方根,然后归一化。 - RoPE 是预计算的,不引入额外可学习参数。只对 Q 和 K 旋转,V 保持不变。
- SwiGLU FFN 有三个权重矩阵,其中 的输出经过 SiLU 激活后与 的输出逐元素相乘,形成门控机制,最后由 降维。
- 残差连接在 Block 的
forward中用简单的加法实现:h = x + self.attn(self.norm1(x), ...)。
5. 主流模型维度配置对比
不同规模的模型本质上是同一套 Decoder Block 结构,只是维度配置不同。下表汇总了几个标志性模型的关键参数:
| 模型 | max_seq_len | |||||||
|---|---|---|---|---|---|---|---|---|
| LLaMA-2-7B | 4096 | 32 | 32 (MHA) | 128 | 32 | 11008 | 32000 | 4096 |
| LLaMA-2-13B | 5120 | 40 | 40 (MHA) | 128 | 40 | 13824 | 32000 | 4096 |
| LLaMA-2-70B | 8192 | 64 | 8 (GQA) | 128 | 80 | 28672 | 32000 | 4096 |
| GPT-3 175B | 12288 | 96 | 96 (MHA) | 128 | 96 | 49152 | 50257 | 2048 |
| Mistral-7B | 4096 | 32 | 8 (GQA) | 128 | 32 | 14336 | 32000 | 32768 |
几个值得注意的规律:
🍎 (每头维度)基本恒定为 128。无论模型多大,每个注意力头处理的维度都是 128。模型变大时增加的是头的数量()和层数(),而非单头维度。这是因为 128 维已经足以让每个头捕捉一种有意义的注意力模式。
🍎 与 的比例。标准 Transformer 中 。但使用 SwiGLU 后,为了保持总参数量不变(三个矩阵 vs 两个矩阵),通常取 ,再向上取整到某个方便的数。比如 LLaMA-2-7B 的 ,取整到 11008(256 的倍数,有利于 GPU 计算对齐)。Mistral-7B 的 略大,因为其设计选择了更大的 FFN。
🍎 GQA 的引入。LLaMA-2-70B 和 Mistral-7B 使用了 Grouped-Query Attention:KV 头数少于 Q 头数。LLaMA-2-70B 用 8 个 KV 头服务 64 个 Q 头(每组 8 个 Q 头共享 1 组 KV),这将 KV Cache 减少到 MHA 的 1/8,大幅降低推理时的显存消耗。
6. 参数量手算教学
能手算模型参数量是 AI Infra 工程师的基本功。知道参数量,才能估算显存需求、通信开销和训练成本。
6.1 通用公式推导
一个标准的 Decoder-only 模型由以下部分组成:
(1)❇️ Token Embedding 层
将 token ID 映射为向量:
其中 是词表大小, 是 。
(2)❇️ 单个 Decoder Block
对于使用 MHA(所有头独立的 KV)和 SwiGLU FFN 的 Block:
Attention 部分四个投影矩阵(不含 bias):
为什么是 ?、、、 每个都是 的矩阵,每个有 个参数。
如果使用 GQA(KV 头数为 ,Q 头数为 ,每头维度 ):
SwiGLU FFN 部分三个矩阵(不含 bias):
其中 是 FFN 中间维度。
RMSNorm 部分(两个,每个有 个参数):
单个 Block 合计:
(3)❇️ 最终的 RMSNorm + 输出头(LM Head)
第一项是最终 RMSNorm 的参数,第二项是 LM Head 的参数(将 映射到 )。
(4)❇️ 模型总参数量
其中 是层数。如果 Embedding 和 LM Head 共享权重(Weight Tying),则减去一个 。
6.2 详细计算:以 LLaMA-2-7B 为例
配置回顾:, , , , ,
🍓 Attention 参数量(单 Block):
| 矩阵 | 形状 | 参数量 |
|---|---|---|
| 4096 x 4096 | 16,777,216 | |
| 4096 x 4096 | 16,777,216 | |
| 4096 x 4096 | 16,777,216 | |
| 4096 x 4096 | 16,777,216 | |
| Attention 小计 | 67,108,864 (67.1M) |
验证:
🍓 FFN 参数量(单 Block):
| 矩阵 | 形状 | 参数量 |
|---|---|---|
| 4096 x 11008 | 45,088,768 | |
| 4096 x 11008 | 45,088,768 | |
| 11008 x 4096 | 45,088,768 | |
| FFN 小计 | 135,266,304 (135.3M) |
验证:
🍓 RMSNorm 参数量(单 Block):
🍓 单 Block 合计:
= 202,383,360 (~202M)
其中 FFN 占比 = 135.3M / 202.4M = 66.8%,Attention 占比 = 67.1M / 202.4M = 33.2%
🍓 整个模型:
| 组件 | 计算 | 参数量 |
|---|---|---|
| Token Embedding | 131,072,000 | |
| 32 层 Block | 6,476,267,520 | |
| 最终 RMSNorm | 4096 | 4,096 |
| LM Head | 131,072,000 | |
| 总计 | 6,738,415,616 (~6.74B) |
如果 Embedding 和 LM Head 共享权重,则减去 131M,约 6.61B。官方标注 “7B” 是近似值。
6.3 练习:LLaMA-2-13B 参数量
配置:, , , , ,
读者可以先自己算,再对照下面的答案:
单 Block:
- Attention: (104.9M)
- FFN: (212.3M)
- RMSNorm:
- 单 Block 合计: (~317M)
整个模型:
- Embedding:
- 40 层 Block:
- 最终 RMSNorm:
- LM Head:
- 总计: (~13.0B)
与官方标注的 13B 吻合。
6.4 Weight Tying 技术
不少模型会让 Token Embedding 和 LM Head 共享同一个权重矩阵。这个技巧叫做 Weight Tying,最早在 2017 年由 Press 和 Wolf 提出。
直觉上可以这样理解:Embedding 层的工作是”将 token ID 映射为语义向量”(从离散空间到连续空间),LM Head 的工作是”将语义向量映射回 token 概率”(从连续空间到离散空间)。这两个操作是互逆的,使用相同的权重矩阵(一个用正矩阵,一个用其转置)是合理的。
Weight Tying 的好处:
- 节省参数:对于 , 的模型,节省 131M 参数,约占 7B 模型的 2%
- 正则化效果:共享权重相当于一种隐式的约束,防止 Embedding 空间和输出空间”漂移”
- 减少显存:少存储一个 矩阵
LLaMA-2 系列使用了 Weight Tying,而 GPT-3 没有使用。是否使用取决于词表大小与模型大小的比例——当词表相对于模型较小时(如 32000 vs 7B),共享带来的参数节省比例很小,但正则化效果仍然有意义。
7. 计算量(FLOPs)估算
知道参数量可以算显存,而知道计算量(FLOPs)则可以估算训练时间和硬件利用率。
7.1 矩阵乘法的 FLOPs
计算量估算的基础是矩阵乘法。一个 的矩阵乘法:
- 结果矩阵有 个元素
- 每个元素需要 次乘法和 次加法
- 总 FLOPs 约为 (乘法和加法各算一次浮点操作)
7.2 单次前向传播的 FLOPs
对于一个有 个参数的 Transformer 模型,处理长度为 的序列时,前向传播的计算量近似为:
这就是 "" 经验法则。这里的直觉是:模型的主要计算都是矩阵乘法,每个参数在前向传播中恰好参与一次矩阵乘法,贡献约 2 FLOPs(一次乘法一次加法),再乘以序列中的 个 token。
更精确地说,这个 只计算了线性层(GEMM)的 FLOPs,忽略了 Attention 中 和 的计算量(这部分与序列长度的平方成正比)。完整的公式是:
其中第二项是 Attention 的计算量(每层每个头有两个 的矩阵乘法,每次贡献 ,共 )。当序列长度 较短时(比如 2048),第二项远小于第一项,"" 是一个好的近似。当 很长(如 128K)时,Attention 的计算量可能接近甚至超过线性层。
7.3 训练 vs 推理的 FLOPs
✳️ 训练时的 FLOPs
训练包括前向传播和反向传播。经验上,反向传播的计算量约为前向传播的 2 倍(需要计算对权重和对输入的梯度)。因此:
对于整个训练过程,如果训练了 个 token:
举个例子:LLaMA-2-7B 用 2 万亿 token 训练:
- FLOPs
如果使用 1000 张 A100(BF16 峰值算力 312 TFLOPS 每张,假设 MFU=50%):
- 有效算力 FLOPS
- 训练时间 秒 = 约 6 天
这与实际公开的训练时间量级相符。
✳️ 推理时的 FLOPs
推理只有前向传播,per token 约 FLOPs。但推理的特殊之处在于 Decode 阶段每步只处理 1 个 token,矩阵乘法退化为矩阵-向量乘(GEMV),GPU 的算力远远用不满,瓶颈变成了显存带宽而非计算能力。所以推理优化更关注显存带宽(Memory Bound)而非峰值算力。
7.4 估算实例
以 LLaMA-2-7B 推理为例,在 A100-80GB 上:
- 单 token Decode FLOPs GFLOPs
- A100 FP16 峰值算力 TFLOPS
- 理论上 FLOPs 只需
但实际一个 token 的 Decode 时间约为 10-20ms。为什么差了几百倍?因为 Decode 是 Memory Bound:需要从 HBM 搬运全部模型权重(13.4 GB FP16),A100 的 HBM 带宽是 2 TB/s,光搬权重就需要 13.4 GB / 2 TB/s = 6.7ms,再加上 KV Cache 的搬运和其他开销,10-20ms 就合理了。
8. 显存规划详解
显存规划是 AI Infra 工程中最常见的实操问题:给定一个模型和一张(或多张)GPU,判断能不能放下,如果放不下该怎么办。
8.1 模型权重显存
模型权重的显存取决于参数量和存储精度:
| 精度格式 | 每个参数占用 | 7B 模型权重大小 | 13B 模型权重大小 | 70B 模型权重大小 |
|---|---|---|---|---|
| FP32 | 4 Bytes | 26.8 GB | 52.0 GB | 280.0 GB |
| FP16 / BF16 | 2 Bytes | 13.4 GB | 26.0 GB | 140.0 GB |
| INT8 | 1 Byte | 6.7 GB | 13.0 GB | 70.0 GB |
| INT4 | 0.5 Bytes | 3.35 GB | 6.5 GB | 35.0 GB |
计算公式:显存 = 参数量 x 每参数字节数
FP16 和 BF16 都是 16 位浮点数,占用相同的显存。BF16 的指数位更多(8 位 vs FP16 的 5 位),数值范围更大,训练时更不容易溢出,是目前训练的主流选择。
8.2 训练态显存:四大组成部分
训练一个模型需要的显存远大于存储权重本身。以混合精度训练(BF16 权重 + FP32 优化器)为例:
(1)模型权重:2 Bytes/param
训练时模型以 BF16 存储,即 Bytes( 为参数量)。
(2)梯度:2 Bytes/param
梯度与权重形状相同,BF16 存储, Bytes。
(3)优化器状态:视优化器而定
这是显存消耗的大头。以最常用的 Adam/AdamW 优化器为例,它需要维护三样东西:
- FP32 参数副本(Master Weights): Bytes。为什么需要 FP32 副本?BF16 只有约 3-4 位有效数字,在更新权重时,如果学习率乘以梯度的值很小(比如 1e-5),BF16 的精度不够表示这个微小的增量,更新就会被”四舍五入”掉。FP32 有约 7 位有效数字,能捕捉这些微小更新。
- 一阶动量(First Moment, m): Bytes。Adam 维护梯度的指数移动平均,用于估计梯度的均值。
- 二阶动量(Second Moment, v): Bytes。Adam 维护梯度平方的指数移动平均,用于估计梯度的方差,实现自适应学习率。
优化器状态合计: = Bytes。
所以人们说”Adam 需要 4x 参数量的显存”,指的就是 = 大约 3-4 倍额外显存:优化器状态 本身就是 BF16 权重 的 6 倍。
(4)Activation Memory(激活值显存)
前向传播中间的激活值需要保存下来供反向传播使用。激活值显存与 batch_size 和序列长度成正比,粗略估算公式为:
其中 是序列长度, 是 batch_size, 是 , 是层数, 是一个常数(约 10-14,取决于是否使用 Activation Checkpointing)。
对于 LLaMA-2-7B,seq_len=2048, batch_size=4, 不使用 Activation Checkpointing:
- 粗估 Bytes (BF16)
- GB
使用 Activation Checkpointing(只保存每层输入,反向时重新计算中间值)可以将激活值显存减少到约 1/3 到 1/5,代价是增加约 33% 的计算量。
✳️ 训练态显存汇总(LLaMA-2-7B,6.7B 参数):
| 组件 | 计算方式 | 显存 |
|---|---|---|
| BF16 模型权重 | 13.4 GB | |
| BF16 梯度 | 13.4 GB | |
| FP32 Master Weights | 26.8 GB | |
| Adam 一阶动量 (FP32) | 26.8 GB | |
| Adam 二阶动量 (FP32) | 26.8 GB | |
| 静态合计 | 107.2 GB | |
| Activation (估算) | batch=4, seq=2048 | ~25.8 GB |
| 总计 | ~133 GB |
133 GB 已经超过了一张 A100-80GB 的显存。这就是为什么训练 7B 模型看起来规模不大,但实际上需要分布式训练(ZeRO、张量并行等)才能跑起来。
8.3 推理态显存:权重 + KV Cache
推理不需要梯度和优化器状态,显存需求简单很多:
(1)模型权重
以 FP16 推理为例:6.7B x 2 = 13.4 GB
(2)KV Cache
每个 token 在每一层需要缓存 K 和 V 各一个向量:
以 LLaMA-2-7B(MHA, )为例:
- 单个 token: Bytes = 512 KB
- seq_len = 4096: KB = 2 GB
- batch_size = 16: GB = 32 GB
✳️ 推理态显存汇总:
| 组件 | LLaMA-2-7B (FP16) | LLaMA-2-7B (INT4) |
|---|---|---|
| 模型权重 | 13.4 GB | 3.35 GB |
| KV Cache (seq=4096, batch=16) | 32 GB | 32 GB (KV 通常仍用 FP16) |
| 其他开销 (框架, buffer) | ~1 GB | ~1 GB |
| 总计 | ~46.4 GB | ~36.4 GB |
注意:即使模型权重量化到 INT4,KV Cache 通常仍然使用 FP16,因为量化 KV Cache 对精度影响较大。近年来有 KV Cache 量化的研究(如 KIVI、KVQuant),可以将 KV Cache 压缩到 INT4 甚至 INT2,但需要额外的校准和精度评估。
8.4 完整规划案例
场景:用单张 A100-80GB 部署 LLaMA-2-13B 进行推理,目标 batch_size=8,最大序列长度 4096,能否装下?
第一步,计算模型权重:
- 13B 参数 2 Bytes (FP16) = 26 GB
第二步,计算 KV Cache:
- LLaMA-2-13B 配置:, (MHA),
- 单 token KV: Bytes = 800 KB
- seq=4096, batch=8: GB
第三步,加上框架开销:
- CUDA 上下文 + 框架 buffer + 临时空间 约 2 GB
第四步,汇总:
- 26 + 25.6 + 2 = 53.6 GB
✳️ 结论:53.6 GB < 80 GB,可以装下,还有约 26 GB 的余量。
但如果想把 batch_size 提高到 16 呢?
- KV Cache 翻倍: GB
- 总计: GB
非常接近 80 GB 上限,几乎没有余量,实际运行大概率 OOM。此时的选择:
- 使用 INT8 量化模型权重: GB,总计 66.2 GB,可行
- 使用 GQA 模型(如 Mistral)减少 KV Cache
- 使用 KV Cache 量化
- 减少最大序列长度
这就是显存规划的实际价值——不是拍脑袋说”应该能跑”,而是精确地算出每一项开销,找到瓶颈,选择合适的优化策略。
9. 主流开源模型架构对比
最后用一张表对比当前主流开源 LLM 的架构选择,帮助建立全局视野:
| 特性 | LLaMA-2 | LLaMA-3 | Mistral-7B | Qwen-2.5 | DeepSeek-V3 |
|---|---|---|---|---|---|
| Attention 类型 | MHA (7B/13B) / GQA (70B) | GQA | GQA | GQA | MLA (Multi-head Latent Attention) |
| KV 头数 (7B 级) | 32 (MHA) | 8 | 8 | 4 | — (MLA 压缩 KV) |
| 位置编码 | RoPE | RoPE | RoPE | RoPE | RoPE |
| 归一化 | RMSNorm (Pre-Norm) | RMSNorm (Pre-Norm) | RMSNorm (Pre-Norm) | RMSNorm (Pre-Norm) | RMSNorm (Pre-Norm) |
| FFN 类型 | SwiGLU | SwiGLU | SwiGLU | SwiGLU | SwiGLU + MoE |
| 是否 MoE | 否 | 否 | Mixtral 版是 | 部分版本是 | 是 (256 专家, Top-8) |
| 词表大小 | 32000 | 128256 | 32000 | 151936 | 129280 |
| 最大上下文 | 4096 | 8192 (可扩展) | 32768 (Sliding Window) | 32768+ | 128K+ |
| 特殊设计 | — | 更大词表、更长上下文 | Sliding Window Attention | 按需扩展 | MLA + MoE 组合 |
几个关键趋势:
GQA 成为标配。从 LLaMA-2 的 MHA 到后续模型几乎全部采用 GQA,核心驱动力是降低推理时的 KV Cache 显存。KV 头数从 32 一路减少到 8 甚至 4,KV Cache 减少了 4-8 倍。
词表持续扩大。LLaMA-2 的 32000 到 LLaMA-3 的 128256,更大的词表意味着更好的多语言支持和更高的 token 效率(同样的文本用更少的 token 表示),但也增加了 Embedding 层的参数量。
MoE 架构兴起。DeepSeek-V3 和 Mixtral 采用混合专家模型,用更大的总参数量但更少的激活参数量(每个 token 只激活少数专家)来提升效果。这给分布式训练和推理带来了新的工程挑战(Expert Parallelism、负载均衡等)。
MLA 的创新。DeepSeek-V3 的 Multi-head Latent Attention 将 KV 投影到低维潜在空间再恢复,在保持模型能力的同时大幅压缩 KV Cache,是对 GQA 思路的进一步发展。
🎯 自我检验清单
学完本文后,检验以下能力:
- 能解释 Decoder-only 架构为什么在大模型时代胜出,至少说出三个理由
- 能在白板上画出完整的 Decoder Block 数据流图,标注 RMSNorm、Masked MHA、SwiGLU FFN、残差连接的位置和顺序
- 能画出因果掩码矩阵(给定序列长度 ),解释上三角 的作用
- 能手算 LLaMA-2-7B 和 13B 的参数量(误差不超过 5%),说清 FFN 和 Attention 的参数比例
- 能用 "" 公式估算训练 FLOPs,用 "" 估算推理 FLOPs
- 能计算给定模型在 FP16、INT8、INT4 下的权重显存
- 能算出 Adam 优化器需要多少显存,并解释为什么需要 FP32 Master Weights
- 给定一个模型配置和 GPU 型号,能完成完整的显存规划(权重 + KV Cache 或 权重 + 梯度 + 优化器 + Activation),判断是否能装下
📚 参考资料
论文
- Attention Is All You Need (Vaswani et al., 2017): https://arxiv.org/abs/1706.03762 — Transformer 原始论文
- LLaMA 2: Open Foundation and Fine-Tuned Chat Models (Touvron et al., 2023): https://arxiv.org/abs/2307.09288 — LLaMA-2 技术报告
- Mistral 7B (Jiang et al., 2023): https://arxiv.org/abs/2310.06825 — Mistral 架构与 Sliding Window Attention
- GLU Variants Improve Transformer (Shazeer, 2020): https://arxiv.org/abs/2002.05202 — SwiGLU 激活函数
- Using the Output Embedding to Improve Language Models (Press & Wolf, 2017): https://arxiv.org/abs/1608.05859 — Weight Tying 技术
- Scaling Laws for Neural Language Models (Kaplan et al., 2020): https://arxiv.org/abs/2001.08361 — 模型规模与性能的缩放规律
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models (Rajbhandari et al., 2020): https://arxiv.org/abs/1910.02054 — ZeRO 显存优化
- DeepSeek-V3 Technical Report (DeepSeek-AI, 2024): https://arxiv.org/abs/2412.19437 — MLA + MoE 架构
教程与博客
- The Illustrated Transformer (Jay Alammar): https://jalammar.github.io/illustrated-transformer/
- Transformer Math 101 (EleutherAI): https://blog.eleuther.ai/transformer-math/ — 参数量和计算量的详细推导
- LLM Training: FSDP vs DeepSpeed (Hugging Face): https://huggingface.co/docs/transformers/main/en/perf_train_gpu_many